Getting started
Overview
An introduction to the Pinecone vector database.
Pinecone Overview
Pinecone makes it easy to provide long-term memory for high-performance AI applications. It’s a managed, cloud-native vector database with a simple API and no infrastructure hassles. Pinecone serves fresh, filtered query results with low latency at the scale of billions of vectors.Vector embeddings provide long-term memory for AI.
Applications that involve large language models, generative AI, and semantic search rely on vector embeddings, a type of data that represents semantic information. This information allows AI applications to gain understanding and maintain a long-term memory that they can draw upon when executing complex tasks.Vector databases store and query embeddings quickly and at scale.
Vector databases like Pinecone offer optimized storage and querying capabilities for embeddings. Traditional scalar-based databases can’t keep up with the complexity and scale of such data, making it difficult to extract insights and perform real-time analysis. Vector indexes like FAISS lack useful features that are present in any database. Vector databases combine the familiar features of traditional databases with the optimized performance of vector indexes.Pinecone indexes store records with vector data.
Each record in a Pinecone index contains a unique ID and an array of floats representing a dense vector embedding.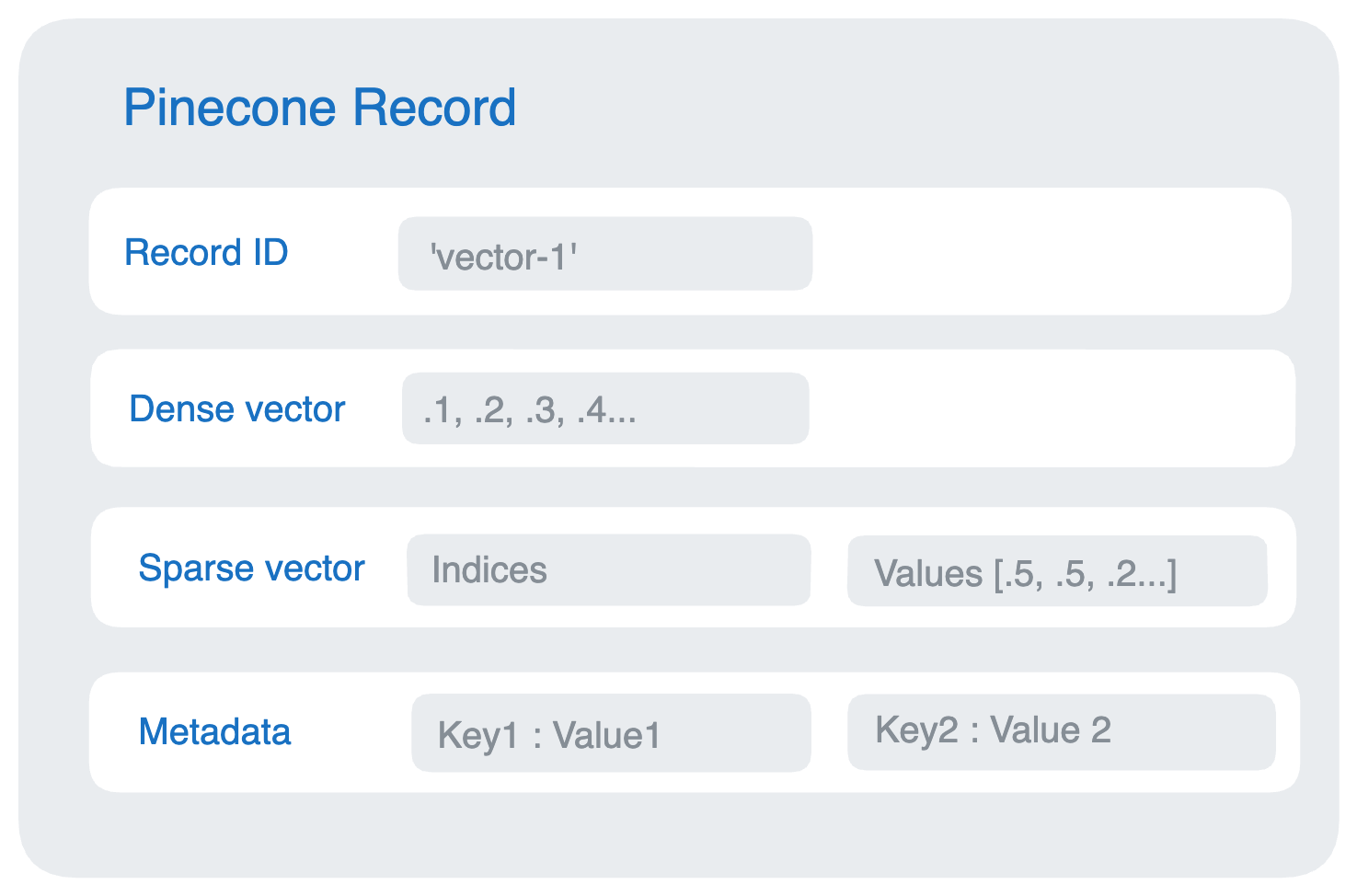 Each record may also contain a sparse vector embedding for hybrid search and metadata key-value pairs for filtered queries.
Each record may also contain a sparse vector embedding for hybrid search and metadata key-value pairs for filtered queries.
Pinecone queries are fast and fresh.
Pinecone returns low-latency, accurate results for indexes with billions of vectors. High-performance pods return up to 200 queries per second per replica. Queries reflect up-to-the-second updates such as upserts and deletes. Filter by namespaces and metadata or add resources to improve performance.Upsert and query vector embeddings with the Pinecone API.
Perform CRUD operations and query your vectors using HTTP, Python, or Node.js.Python