Amazon Bedrock
Pinecone as a Knowledge Base for Amazon Bedrock
Users can now select Pinecone as a Knowledge Base for Amazon Bedrock, a fully managed service from Amazon Web Services (AWS) for building GenAI applications. The Pinecone vector database is a key component of the AI tech stack, helping companies solve one of the biggest challenges in deploying GenAI solutions — hallucinations — by allowing them to store, search, and find the most relevant and up-to-date information from company data and send that context to Large Language Models (LLMs) with every query. This workflow is called Retrieval Augmented Generation (RAG), and with Pinecone, it aids in providing relevant, accurate, and fast responses from search or GenAI applications to end users. With the release of Knowledge Bases for Amazon Bedrock, developers can integrate their enterprise data into Amazon Bedrock using Pinecone as the fully-managed vector database to build GenAI applications that are:- Highly performant: Speed through data in milliseconds. Leverage metadata filters and sparse-dense index support for top-notch relevance, ensuring quick, accurate, and grounded results across diverse search tasks.
- Cost effective at scale: Start for free on the starter plan and seamlessly scale usage with transparent usage-based pricing. Add or remove resources to meet your desired capacity and performance, upwards of billions of embeddings.
- Enterprise ready: Launch, use, and scale your AI solution without needing to maintain infrastructure, monitor services, or troubleshoot algorithms. Pinecone meets the security and operational requirements of enterprises.
What are Agents for Amazon Bedrock?
In Bedrock, users interact with Agents that are capable of combining the natural language interface of the supported LLMs with those of a Knowledge Base. Bedrock’s Knowledge Base feature uses the supported LLMs to generate embeddings from the original data source. These embeddings are stored in Pinecone, and the Pinecone index is used to retrieve semantically relevant content upon the user’s query to the agent. Note: the LLM used for embeddings may be different than the one used for the natural language generation. For example, you may choose to use Amazon Titan to generate embeddings and use Anthropic’s Claude to generate natural language responses. Additionally, Agents for Amazon Bedrock may be configured to execute various actions in the context of responding to a user’s query - but we won’t get into this functionality in this post.What is a Knowledge Base for Amazon Bedrock?
A Bedrock Knowledge base ingests raw text data or documents found in Amazon S3, embeds the content and upserts the embeddings into Pinecone. Then, a Bedrock agent can interact with the knowledge base to retrieve the most semantically relevant content given a user’s query. Overall, the Knowledge Base feature is a valuable tool for users who want to improve their AI models’ performance. With Bedrock’s LLMs and Pinecone, users can easily integrate their data from AWS storage solutions and enhance the accuracy and relevance of their AI models. In this post, we’ll go through the steps required for creating a Knowledge Base for Amazon Bedrock as well as an agent that will retrieve information from the knowledge base.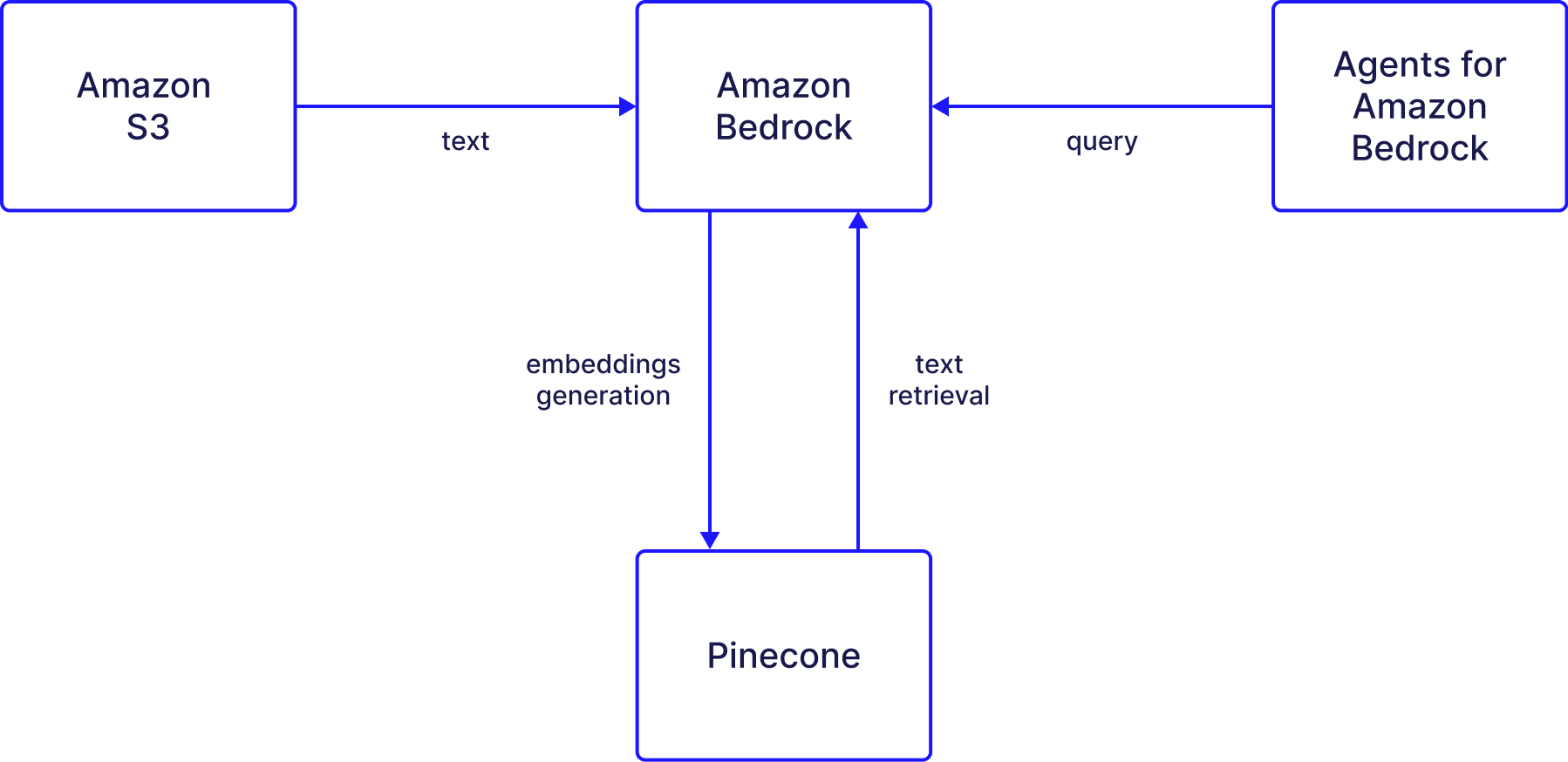
Process overview
The process of using the Bedrock knowledge with Pinecone works as follows:- Data is uploaded to Amazon S3
- The data is pulled by Bedrock and embeddings are created
- The embeddings are saved in Pinecone.
- The knowledge base can now reference the data saved in Pinecone.
- An agent can interact directly with the Knowledge Base, which will apply the same Embeddings FM to retrieve the semantically relevant content.
Setting up your Knowledge Base for Amazon Bedrock
Creating a Pinecone index
The knowledge base we’ll build is going to rely on a Pinecone index. After signing up to Pinecone, follow the quickstart guide to create your Pinecone index, and retrieve your index’s endpoint andapiKey from the Pinecone console.
Setting up secrets
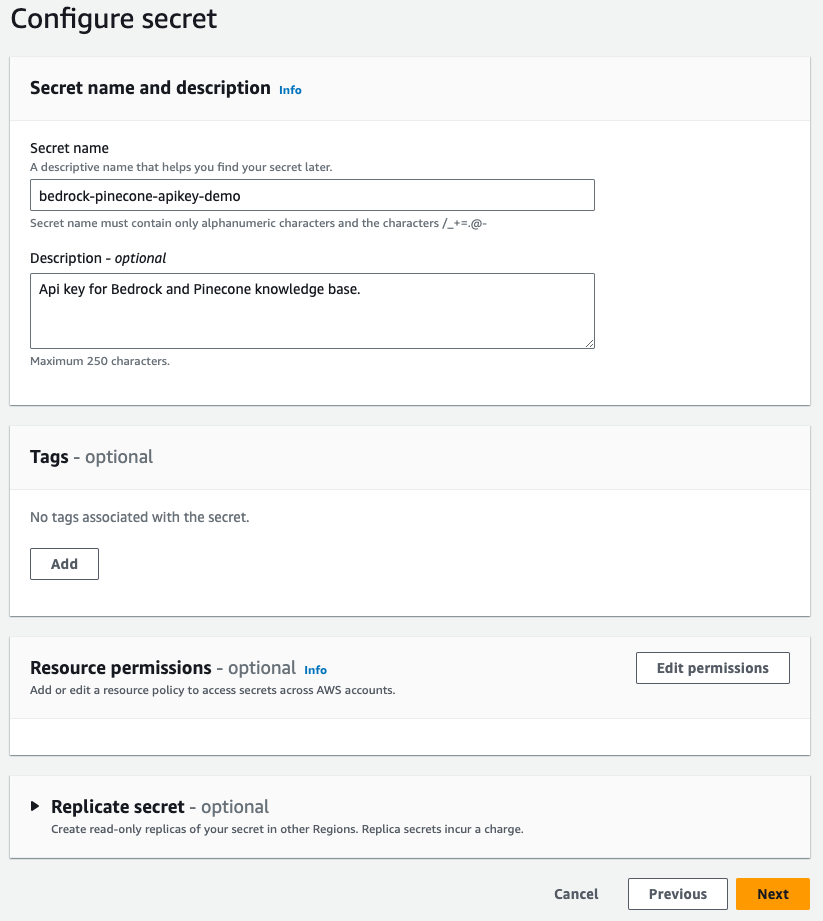
After setting up your Pinecone index, you’ll have to create a secret in AWS’s Secrets Manager.- Head to the Secrets Manager and create a new secret.
- Define your secret name.
- Provide a helpful description and click next.
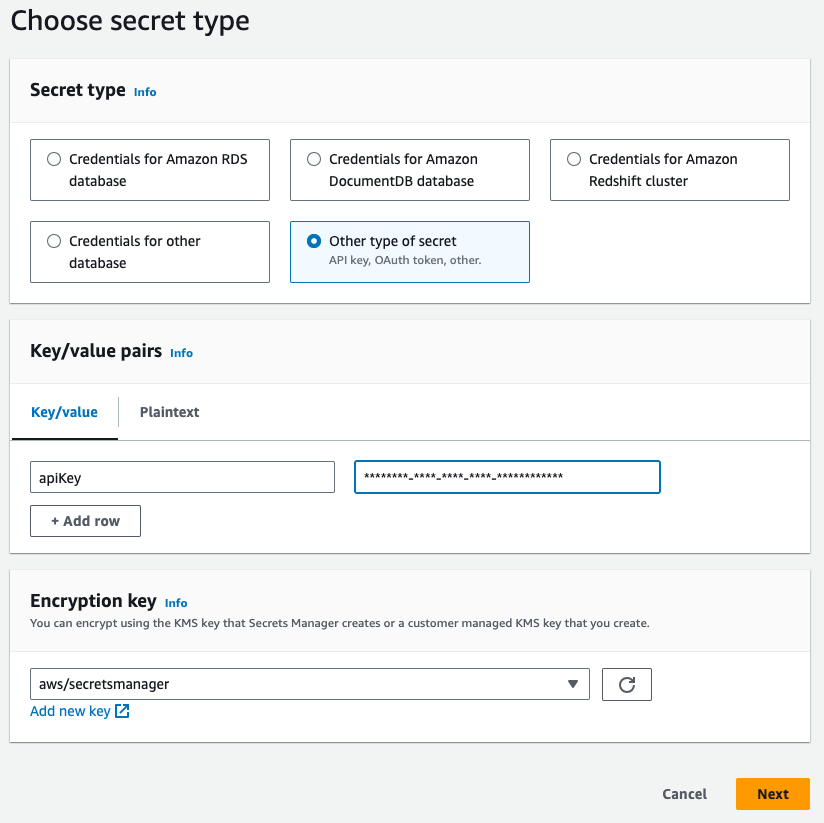
- Select “Other type of secret”.
- Create a new Key/value pair with the key
apiKeyand then paste your Pinecone API key as it’s corresponding value. - Click next to save your key.
- Select all the default options in the next screen.
- Copy your new secret’s ARN so that it’s available later.
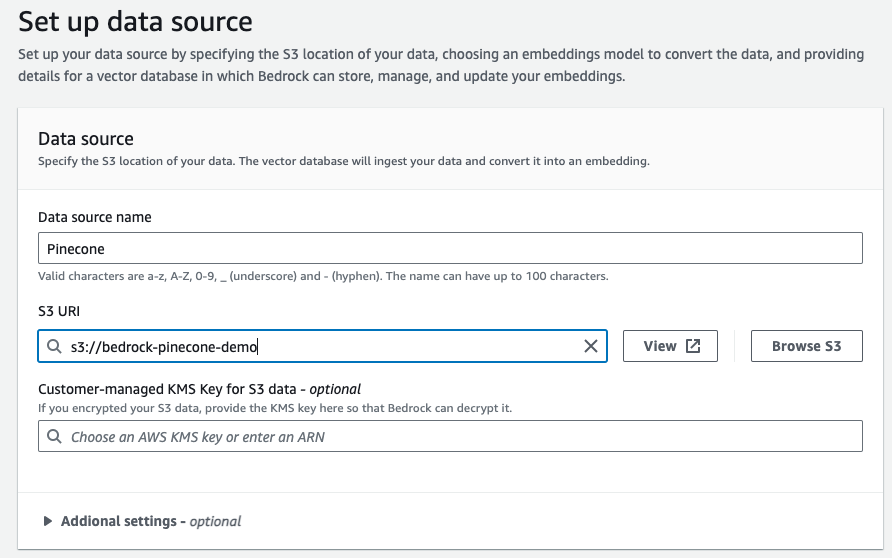
Set up your Data source
Our knowledge base is going to draw on data saved in S3. This data will be embedded and then saved in Pinecone.- Create a new bucket in S3.
- Once the bucket is created, you’ll see the following:
- Upload a CSV file to the newly created S3 bucket.
- Once your data is uploaded, you’ll see the following:
- Save your bucket’s address (
s3://…) for the following configuration steps.
Create the knowledge base
After setting up our data source, it’s time to configure the knowledge base itself.- Start by providing a name and description for your knowledge base.
- Select the IAM role for the knowledge base.
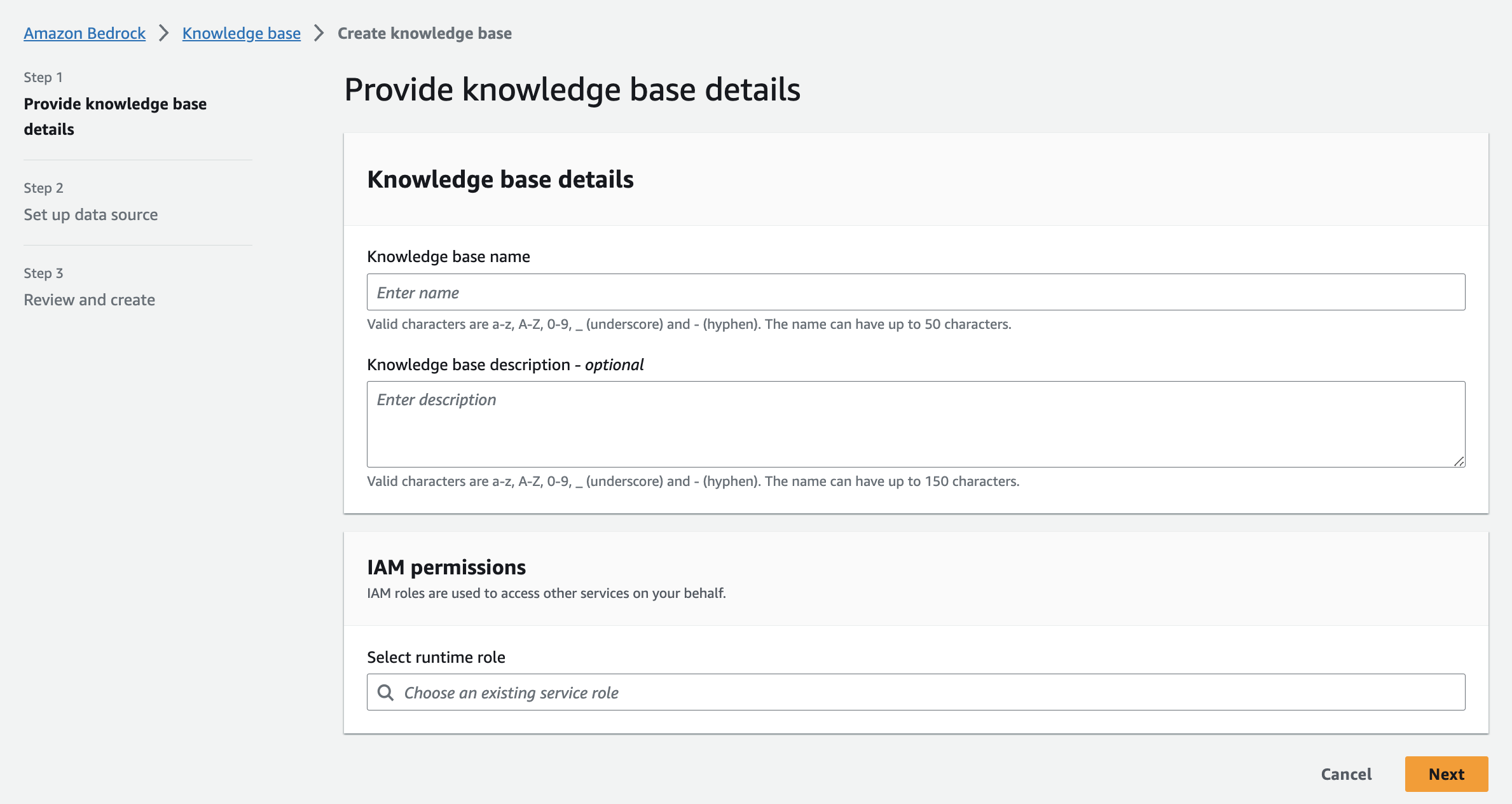
- Select the S3 bucket created earlier.
Connect Pinecone to the Knowledge Base
- From the “Select an existing database” options, select Pinecone.
- Mark the check box for authorizing AWS to access your Pinecone index.
- Provide the Pinecone index endpoint retrieved from the Pinecone console as the “Connection String”.
- Provide the secret ARN you created earlier for the “Credentials secret ARN” field.
- Provide the name the text field you’d like to be embedded.
- Provide the field name that will be used for metadata managed by Bedrock (e.g.
metadata)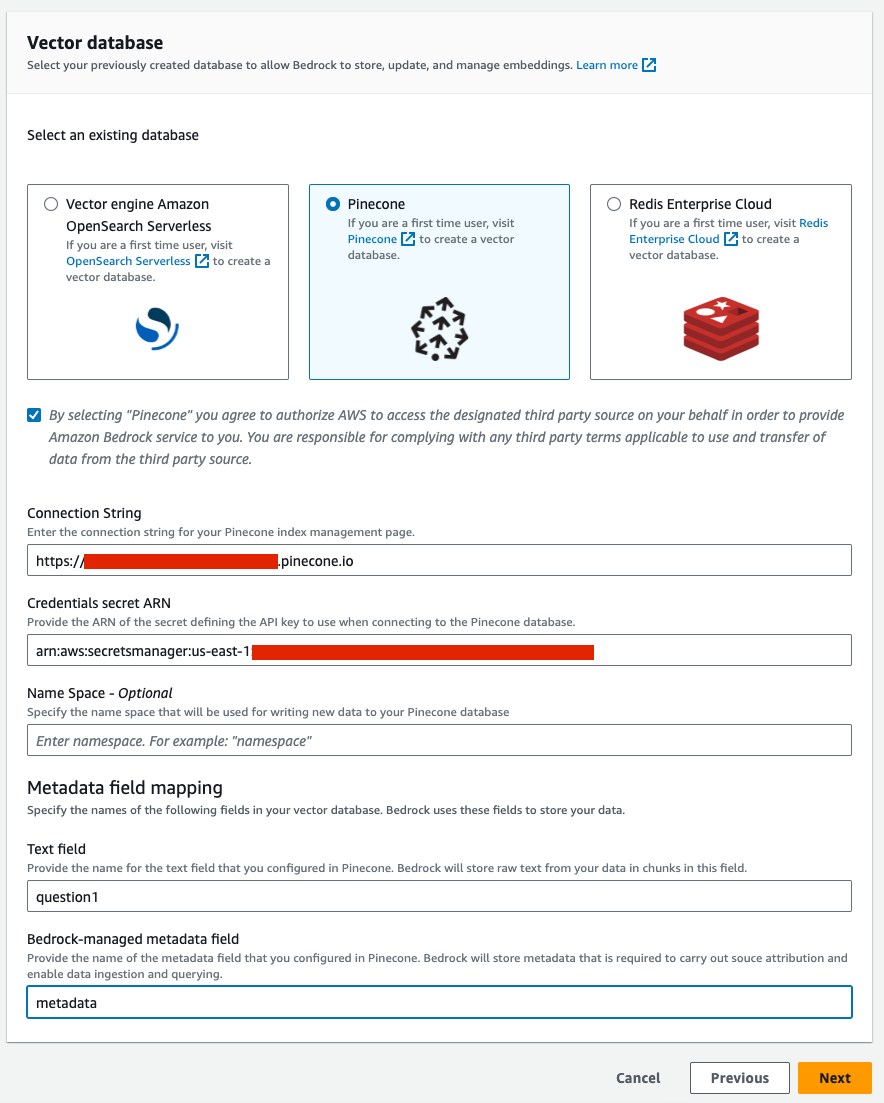
- Review your selections and complete the creation of the knowledge base.
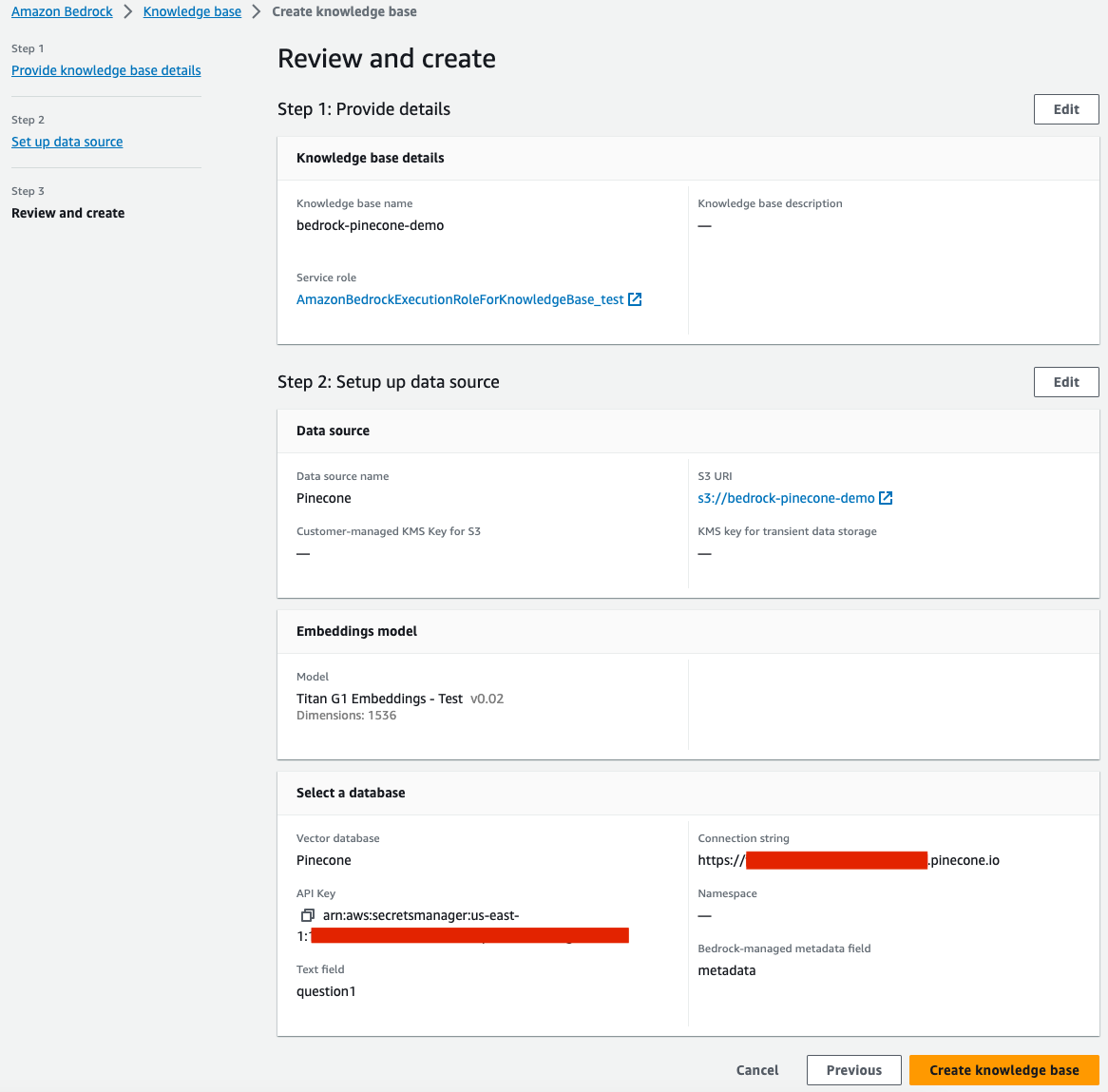
- Back in the knowledge base details page, choose Sync for the newly created data source, and whenever you add new data to the data source, to start the ingestion workflow of converting your Amazon S3 data into vector embeddings and upserting the embeddings into the vector database. Depending on the amount of data, this whole workflow can take some time. 
Setting up an Agent
Once the knowledge base is created, all that’s left is to create an agent that will use it for retrieval.- Start by providing the basic information for your agent, such as name description etc. You will also have to select an existing IAM role for you agent or create a new one.
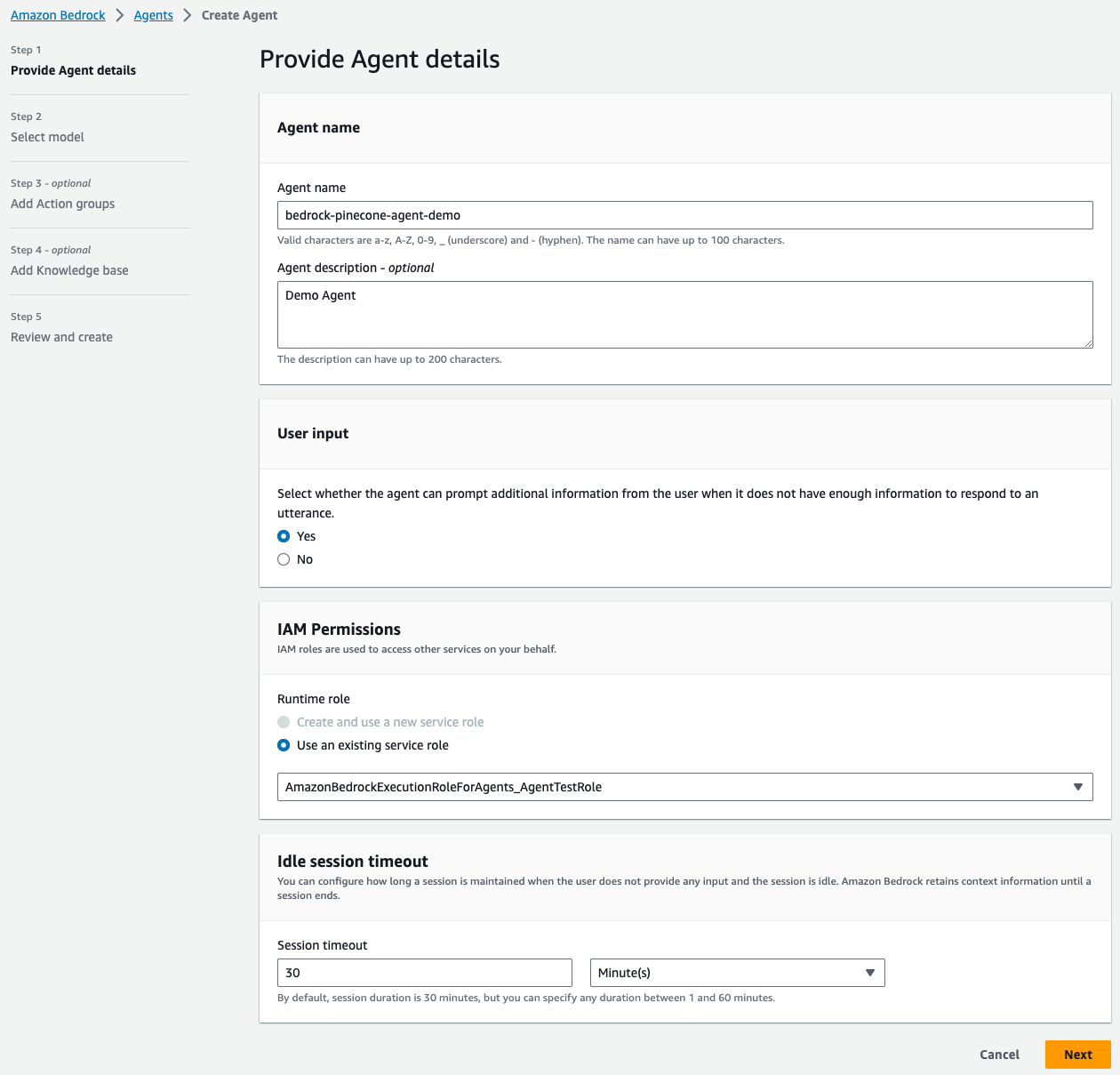
- Select the LLM provider and model you’d like to use. As of the time of writing this post, you’ll only be able to choose Anthropic’s Claude V1 model - but more providers and models will be available soon.
- Provide instructions for the agent. These will define what the agent is trying to accomplish. For example, an instruction could be “You are a chat agent that will be answering frequently asked questions about Amazon S3”.
- You can optionally select potential actions that can be executed by the agent. As mentioned before, we won’t cover this functionality in this post.
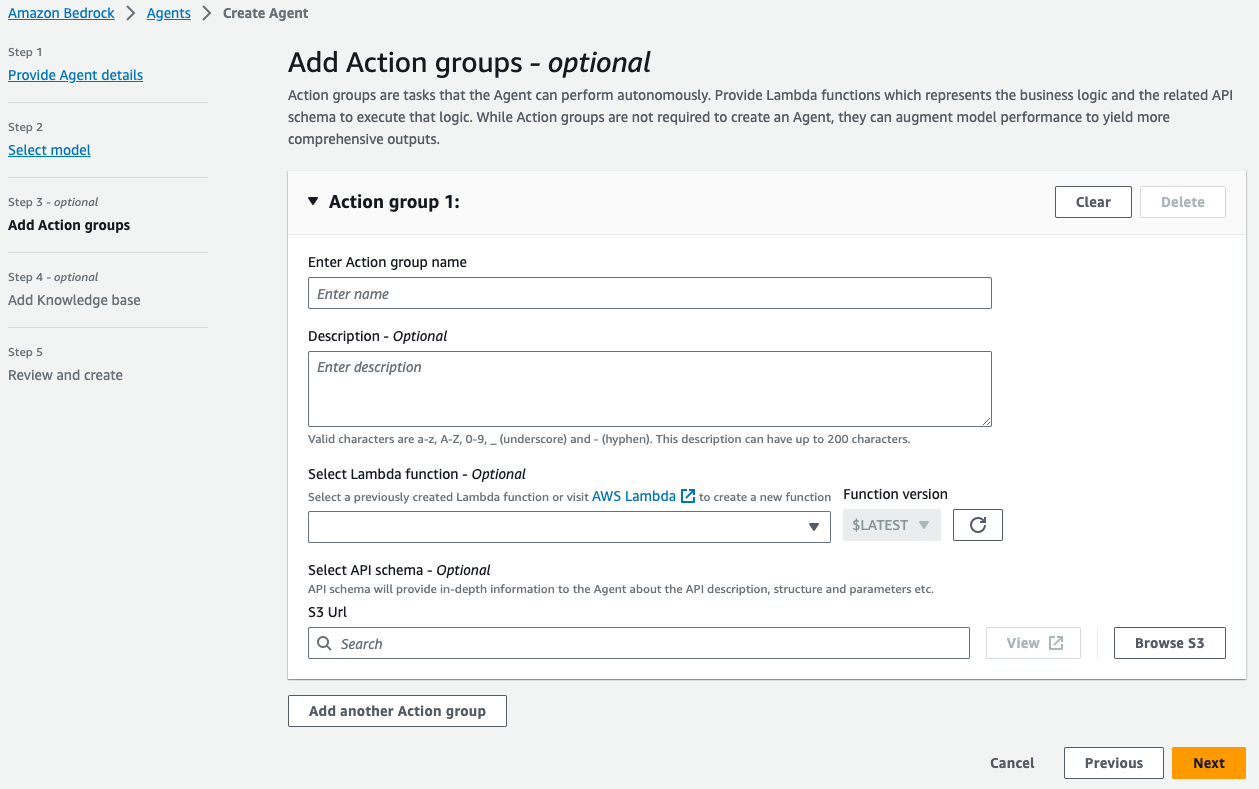
- Select the knowledge model created previously, and define the instructions for the agent when interacting with this knowledge model. These instructions will tell the agent when to use the knowledge base and what type of information could be found in the knowledge base. Note you may configure an agent to use multiple knowledge bases.
- Finally, review and create your agent.
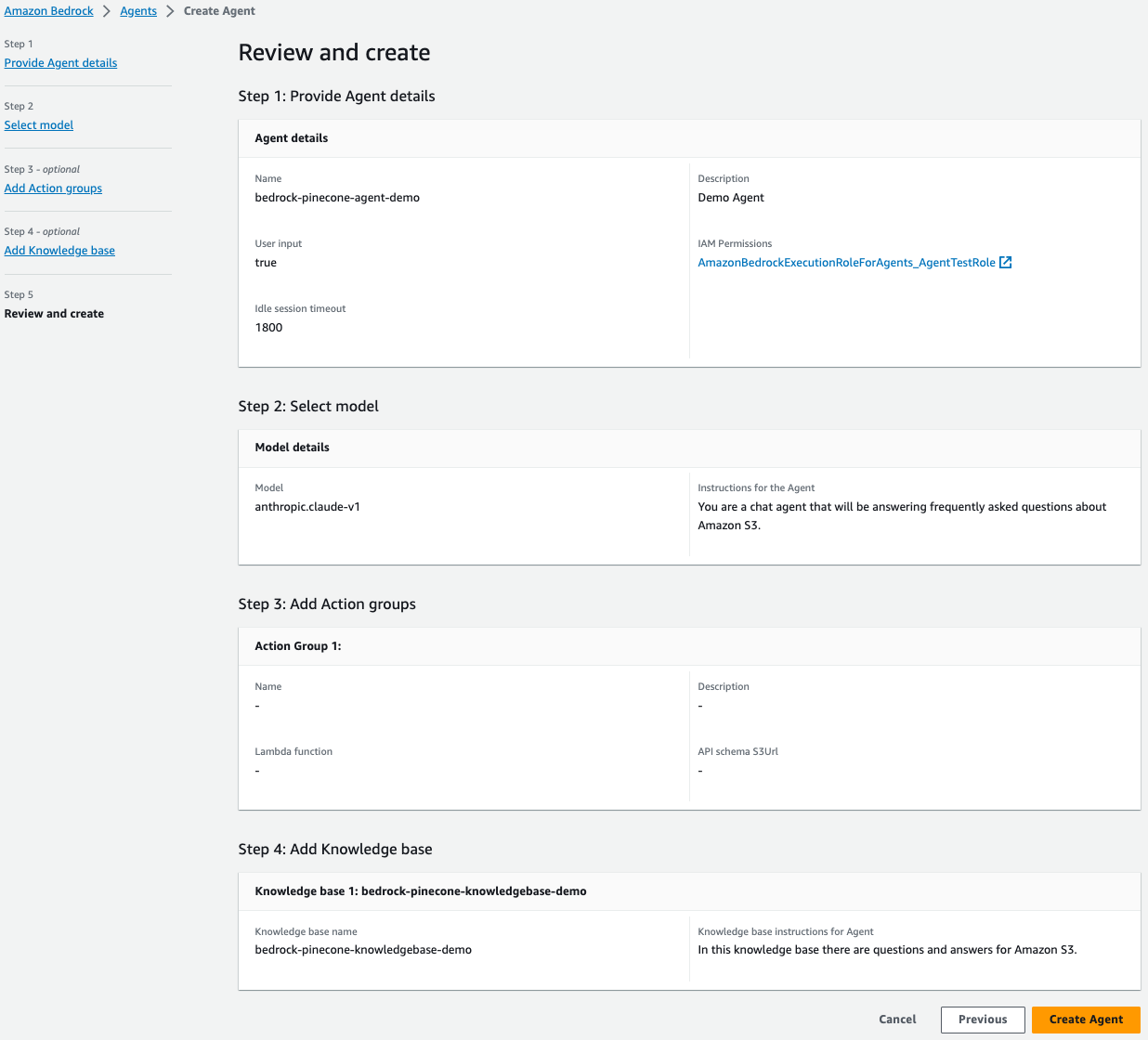
 Your agent is now set up and ready to go! In the next section, we’ll review how to interact with the newly created agent.
Your agent is now set up and ready to go! In the next section, we’ll review how to interact with the newly created agent.
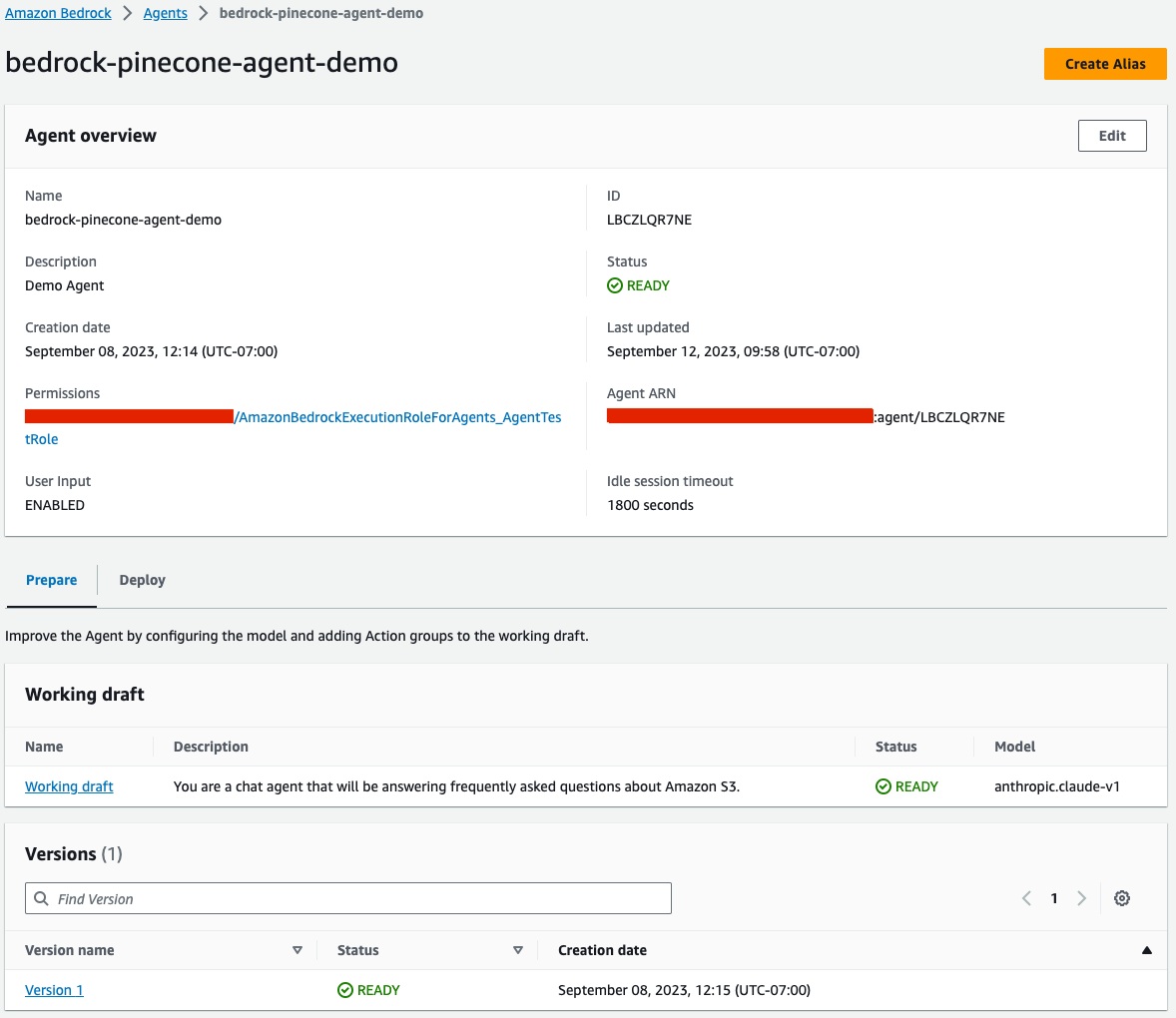
Creating an Alias for your agent
In order to deploy the agent, we need to create an alias for it which points to a specific version of the agent.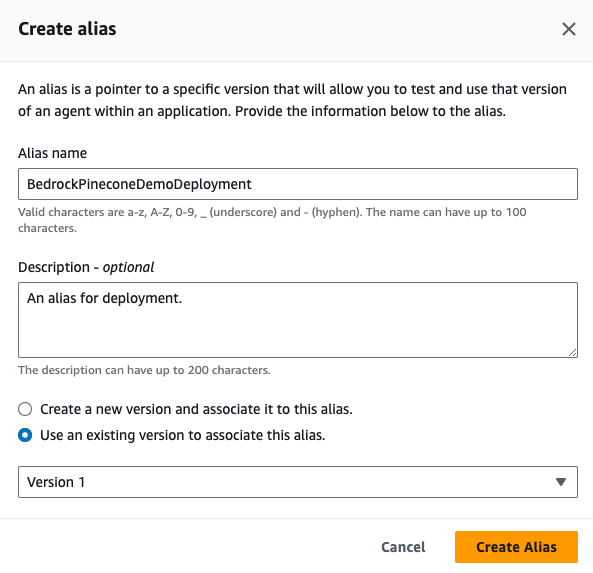 Once the alias is created, we’ll be able to see it in the agent view:
Once the alias is created, we’ll be able to see it in the agent view:
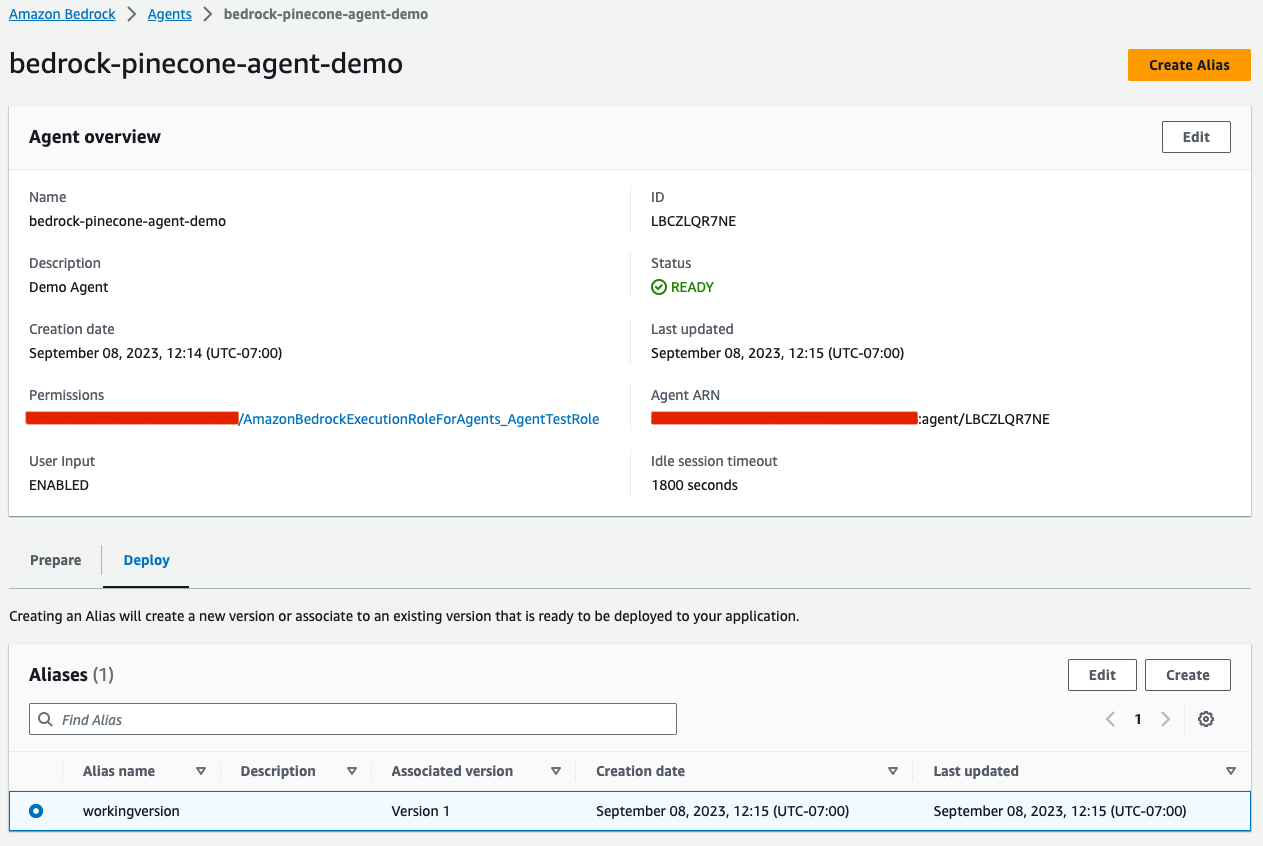
Testing the Bedrock Agent
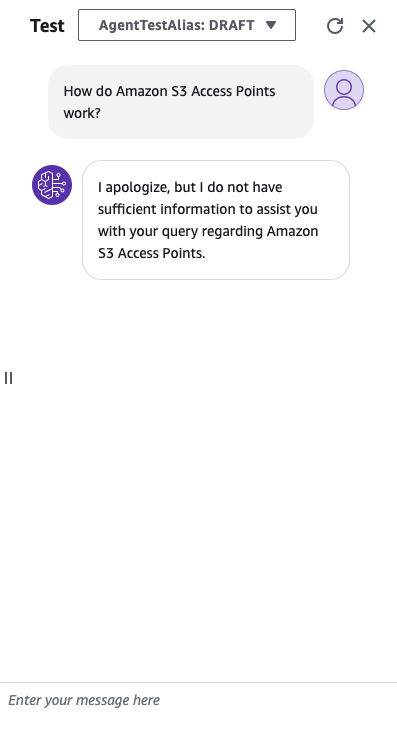
To test the newly created agent, we’ll turn to the playground on the right of the screen when we open the agent.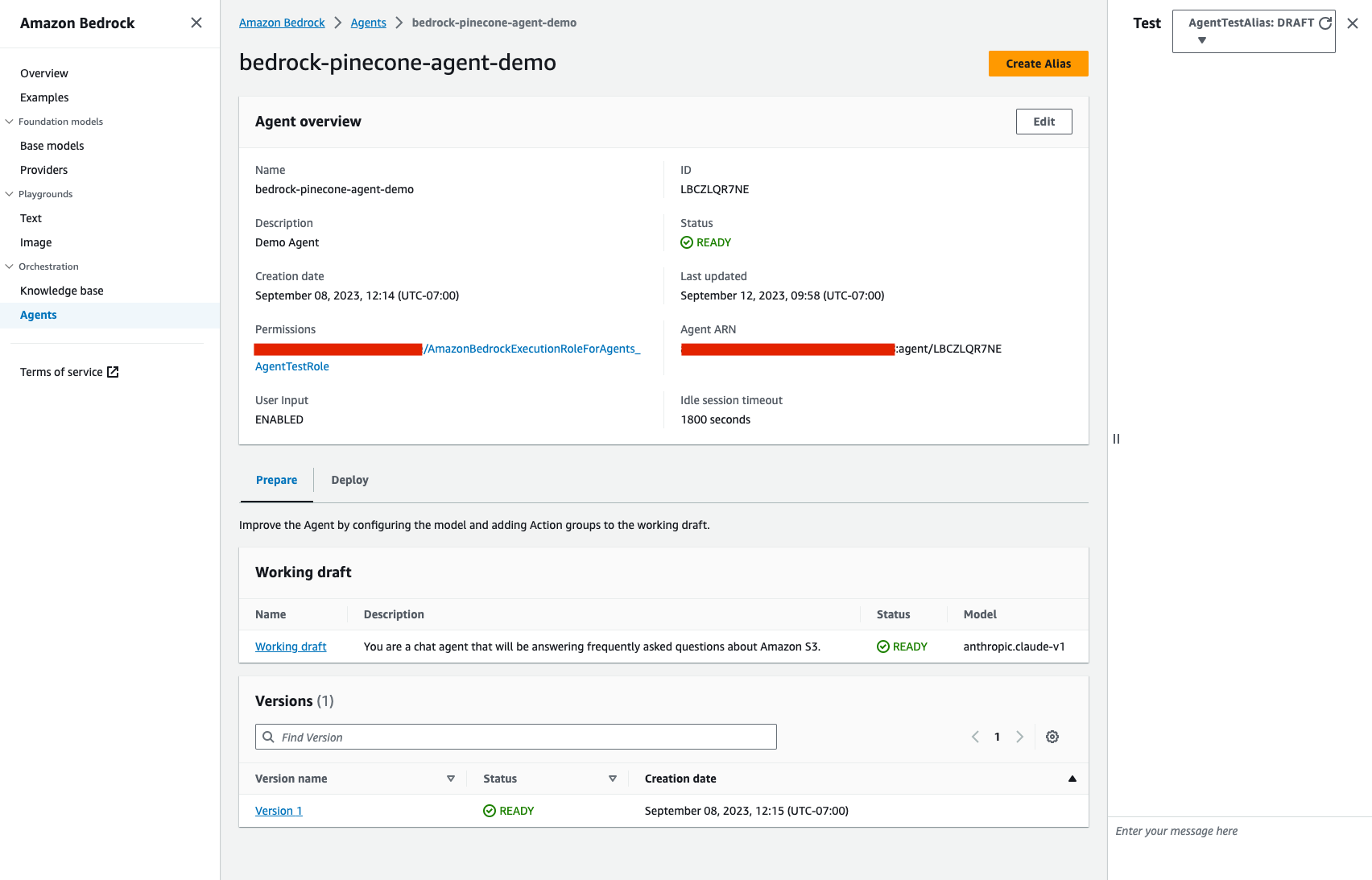 In this example, we used a FAQ document for Amazon’s S3 Access Points for our source data. When we ask a question about this topic. If we ask a question about this topic using an agent without a knowledge base, we’ll get the following response:
In this example, we used a FAQ document for Amazon’s S3 Access Points for our source data. When we ask a question about this topic. If we ask a question about this topic using an agent without a knowledge base, we’ll get the following response:
 Let’s compare that with an agent that is utilizing a knowledge base:
Let’s compare that with an agent that is utilizing a knowledge base:
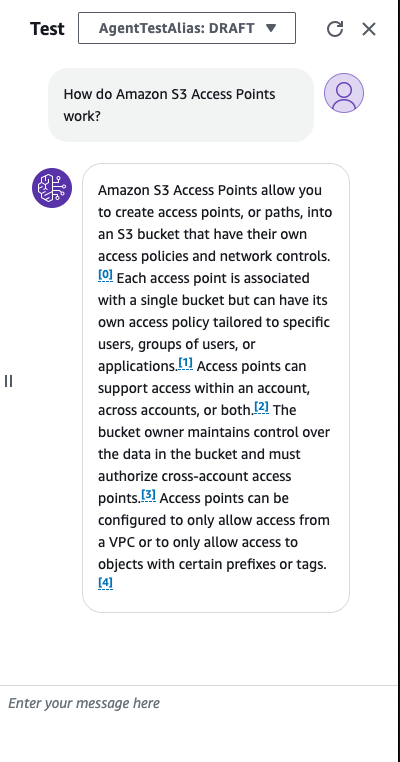 As we can see the answer is much more detailed, and includes multiple citations that point to the data source used to create the knowledge base. This is the power of the RAG pattern it ensures that the LLM can base it’s reposes on information that is semantically relevant to the user query, while preserving the references to the original data.
As we can see the answer is much more detailed, and includes multiple citations that point to the data source used to create the knowledge base. This is the power of the RAG pattern it ensures that the LLM can base it’s reposes on information that is semantically relevant to the user query, while preserving the references to the original data.